在上次的体验评价《[[大模型类AI产品的个人使用体验及评价(20250226更新)|大模型类AI产品的个人使用体验及评价(20250226更新)]]》基础上,重新把大模型类AI产品分为四个类别:通用大模型产品(不同端同一产品名称视为同一产品,比如腾讯元宝桌面端和移动端视为同一产品)、笔记类大模型产品(原来叫知识库类大模型产品,感觉帽子有点高,还是实在一点比较好)、其他大模型应用产品、大模型云服务产品。后续随着AI产品的不断发展和延伸,类别划分和产品所属类别可能仍会发生变化。
- 通用大模型产品:产品的核心功能是通过大模型生成文本(这类产品主要考虑文字输出,图片和视频输出单独考虑)来和用户进行问答交互,本文以安卓端、Windows端体验为主。
- 笔记类大模型产品:嵌入笔记APP产品的大模型AI助手,可以进行直接问答或者基于知识库问答,以及其他功能。
- 大模型应用类产品:使用大模型的文本生成功能更好的赋能自己的产品,产品本身的功能不是和用户对话输出信息,而是画图、编程、做PPT、写公式等。
- 大模型云服务产品:云服务厂商给大模型应用产品的开发者提供的大模型部署和接口服务,包括自研大模型和开源大模型。
通用大模型产品
综合考虑下来,主要从以下几个方面评价产品:使用快捷性、颜值、多端体验、日常问答表现、深度研究表现。其中,前三者体现厂商的客户洞察能力,但是应该随着产品不断迭代很快能力拉平,后两者体现厂商的技术实力,后续可能会拉开差距。 使用便捷性:包括启动、退出和运行速度以及使用便捷性(比如桌面端快捷键的使用便捷性,移动端界面的复杂性。 颜值:主要看个人眼缘。 多端体验:是否支持多端体验,先看有没有,再看是否有协同体验。 日常问答表现:主要评价大模型对日常问题的回答的质量。 深度研究表现:主要评价在大模型对某一主题生成的深度内容的质量。由于时间有限,还没有来得及深入研究和对比,只是用了“帮我输出一份华为从成立到现在的每一年的销售额、利润、人数的数据表,且需注明每一个数据的来源”这个主题测了几个大模型,还是有很大差别。
评价全靠个人体验,1星表示不好用,2星表示能用,3星表示一般,4星表示优秀,5星表示卓越。
腾讯元宝(DeepSeek)
使用便捷性:移动端点一下能快速打开,输入既可以打字也能语音,用完在屏幕边缘划一下能马上退出,不需要多余的动作,简单直接而有效,桌面端启动速度也很快,并且已经能够很方便的使用快捷键了,运行速度都还不错,在选中deepseek后不再自行恢复到混元模型,可以给到4星★★★★,比上次评价时提升一星,不能给到5星是因为找过往的问题不太方便。
颜值:以deepseek为4星,元宝也可以给4星★★★★。比上次评价时提升一星,主要是元宝这段时间更新很快,颜值相对上次评价时还是半成品有所提升,但总还是觉得有点不太得劲的地方,有提升空间。
多端体验:既有移动端也有桌面端,体验都还不错,给到4星★★★★。
日常问答表现:目前作为主力用了一个多月,基本能满足日常问答使用,没有看出来比其他模型差的地方,还能够输出比较靠谱的python代码,直接帮助解决一些Excel数据处理的事情,以官方DeepSeek表现为4星,综合可以给4星★★★★。但是在推荐优质医院方面,所有大模型包括元宝在开启联网搜索的情况下,输出的医院都是些乱七八糟的医院,但是在不开启联网搜索的情况下输出的医院反而是比较准确的,这说明联网搜索结果反而会污染大模型的回答结果,我推测可能跟目前联网搜索的实现方式有关。我估计:目前的联网搜索都只是比较随便的搜出几十个网页,然后也不知道依靠什么原则再选出其中的一些网页发给大模型,然后大模型就把这些网页资料当做圣旨再反馈出来,而不是大模型根据需要在合适的时候自己选择搜索网页,然后识别并判断网页结果的可靠性,然后综合自己的知识再输出最可靠的结论。未来厂商即便不断迭代产品,估计也只能依赖自己的算法优化搜索结果,但是短期内可能不可能让大模型自行完成根据需要搜索吧,这样看来,大模型要取代人类还是任重而道远的,但是谁又说得好呢?
深度研究表现:这一块以Google Deep Research为4分,腾讯元宝给1星★,下图为元宝的答案,可以说是有点烂了,应该和上面说的联网搜索能力的实现方式有关。
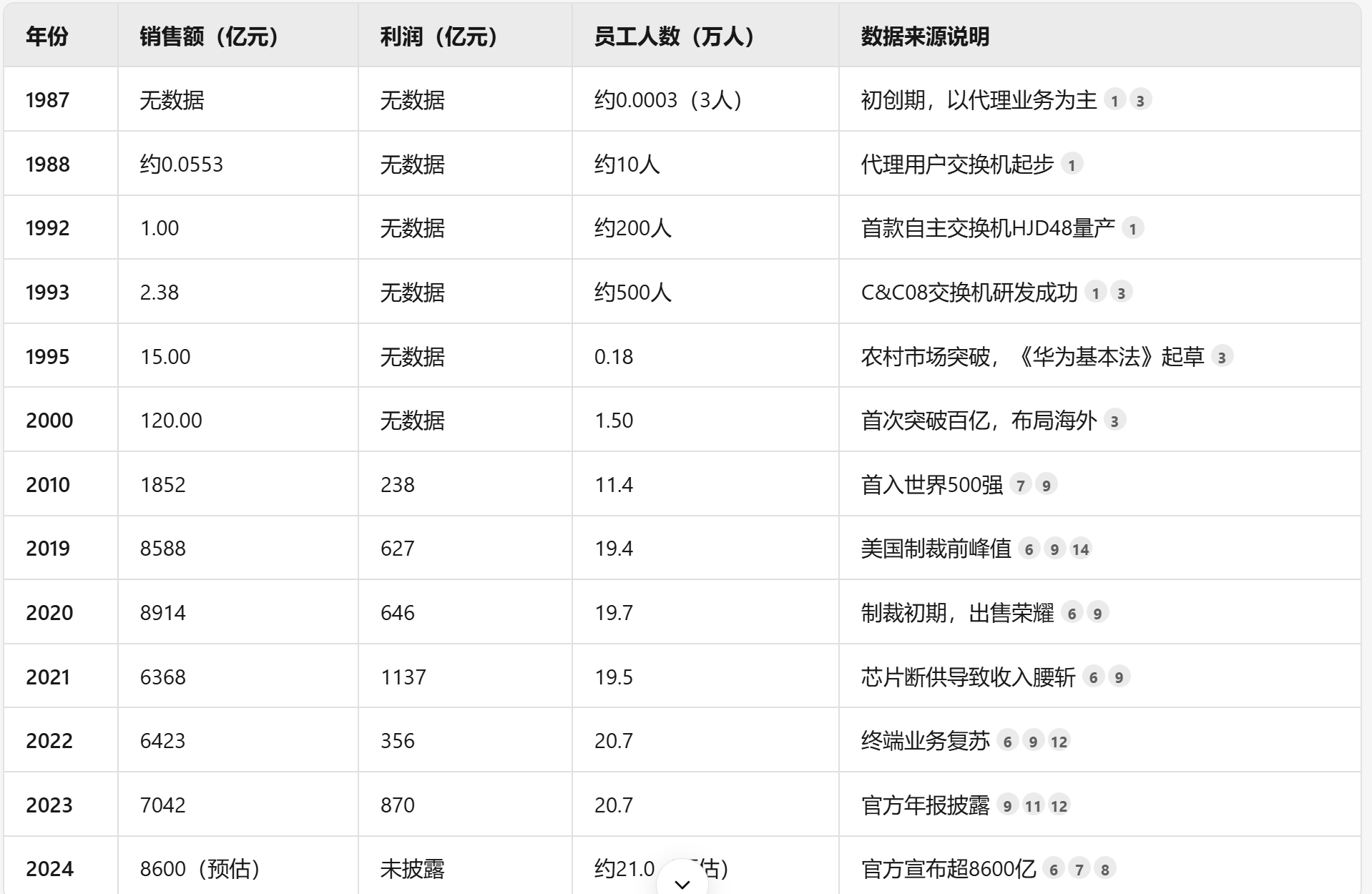 综合评价:腾讯做产品还是有谱的,模型使用上心态也比较开放,目前感觉潜力很大。
综合评价:腾讯做产品还是有谱的,模型使用上心态也比较开放,目前感觉潜力很大。
DeepSeek
使用便捷性:跟腾讯元宝一样,给到4星★★★★。
颜值:跟腾讯元宝一样,给到4星★★★★。
多端体验:没有桌面端,已经很少用了。给到2星★★。
日常问答表现:用了元宝后没有重点使用了,目前看起来没有和元宝有系统性的差异,给到4星★★★★。
深度研究表现:跟元宝一样,1星★,不知道思考了个啥。
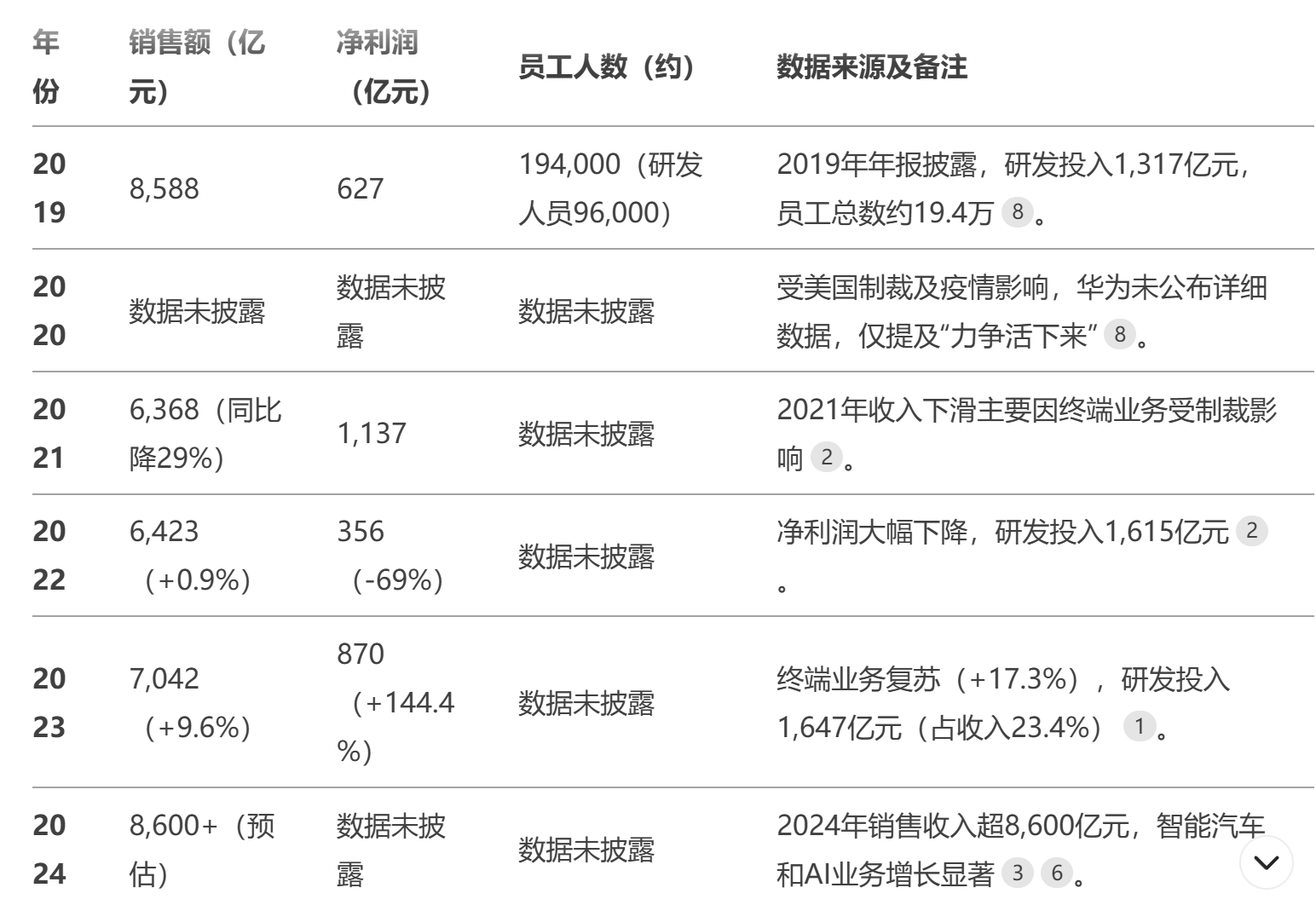 综合评价:DeepSeek未来可能是要往基础模型提供商的方向发展了,用户层面的产品体验目前还看不到很大的潜力。
综合评价:DeepSeek未来可能是要往基础模型提供商的方向发展了,用户层面的产品体验目前还看不到很大的潜力。
豆包
使用便捷性:上一次的评价不变,2星★★。
移动端:目前豆包和讯飞星火是把主通用模型和其他垂直领域智能体设计成聊天列表样式的,启动的时候是直接打开主通用模型的聊天界面,但是退出的时候会先退到聊天列表,再退出应用,所以用完需要滑两下退出。这种设计目前不太理解,只能给2星★★。 桌面端:优点一是可以使用快捷键快速调出搜索框向AI提问,这个功能未来说不定是标配(目前元宝也已经有了),二是可以在其他软件弹出取词工具栏,不管是AI搜索还是查单词都比较好用。缺点:基于chromium开发,内存占用太大,日常1.5G起步,但是作为浏览器体验又不如Chrome。
颜值:中规中矩吧,3星不变★★★。
多端体验:有移动端也有桌面端,怎么着也要给个3星★★★,虽然桌面端的内存占用实在有点一言难尽。
日常问答表现:现在也有了深度思考,但是已经没有那么多问题去深度体验了,先给3星吧★★★。
深度研究表现:2星吧★★,至少年份数据是全的。
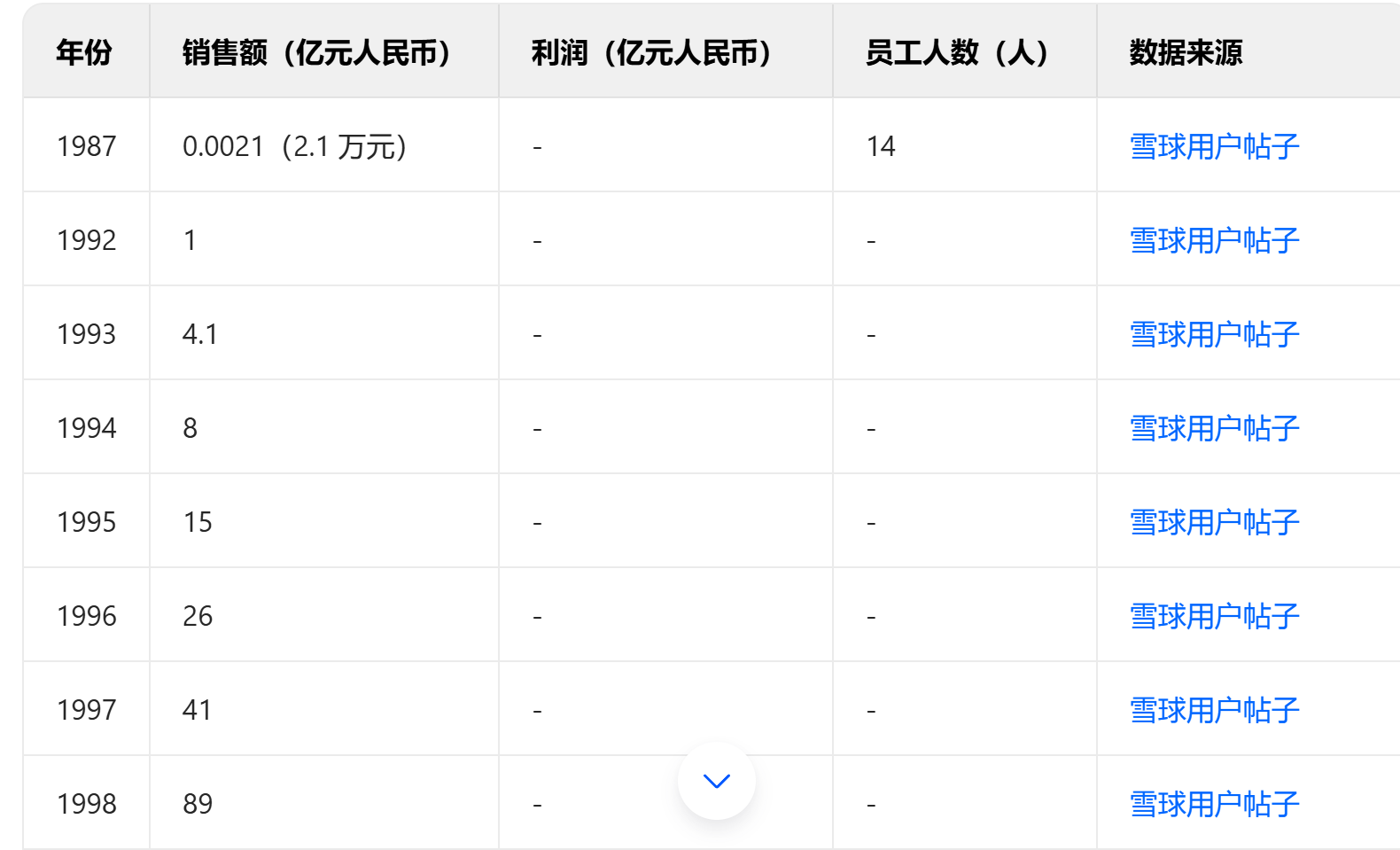 综合评价:暂时还没有看到有什么新的突破。
综合评价:暂时还没有看到有什么新的突破。
Gemini
使用便捷性:移动端基本算是用不了,给1星★。
颜值:不予评价。
多端体验:不予评价。
日常问答表现:暂时没有深入用,不予评价。
深度研究表现:把Gemini提到前面来,主要是用了一把Google Deep Research,感觉确实是有点谱,可以看到它的实现逻辑是基于需要进行网页搜索,最终给出的结果至少从篇幅看是很有谱的,可以给到4星★★★★。我觉得对做研究应该还是有一点帮助的,有时间可以试试更深度的研究问题。

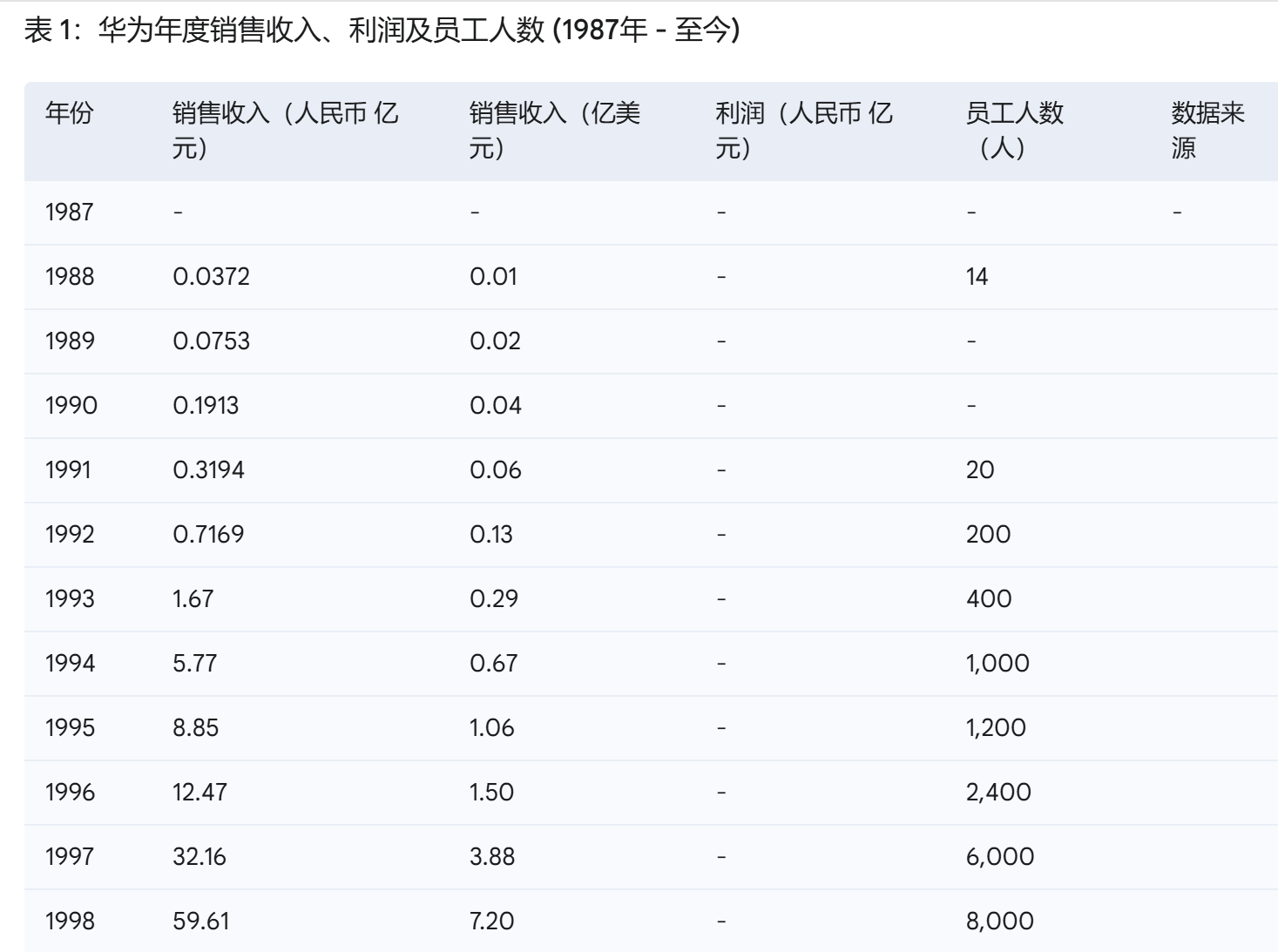
Kimi
使用便捷性:kimi、通义和文小言在退出时都会弹出“再按一次退出应用”的提示,需要多滑一次才能退出,这种设计很有中国特色,也很让人讨厌,所以给3星★★★。
颜值:3星★★★。
多端体验:桌面端比之前大有进步,跟元宝体验差不多,给到4星★★★★。
日常问答表现:深度感觉是比deepseek有差距,但毕竟还是有深度思考,给3星★★★。
深度研究表现:也是1星★。
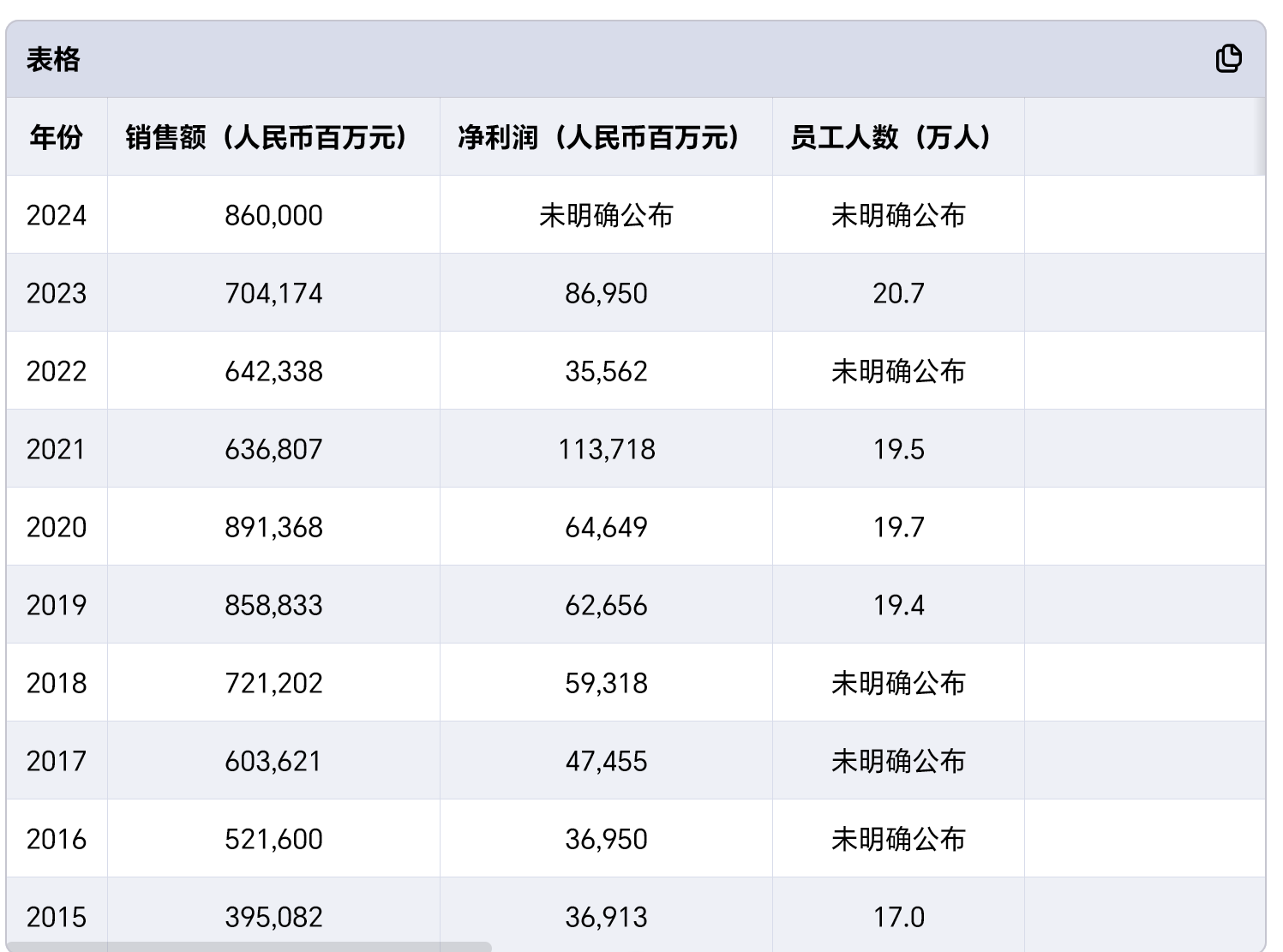 综合评价:Kimi应该是AI时代崛起的一个新秀,但主要是靠买量推广起来的,能否存活尚不确定,但值得持续观察,目前作为备选。
综合评价:Kimi应该是AI时代崛起的一个新秀,但主要是靠买量推广起来的,能否存活尚不确定,但值得持续观察,目前作为备选。
Cherry Studio
由于cherry studio只是一个桌面客户端,本身并不提供大模型,大模型也是取决于用户自己选择的api,所以不评价日常问答表现和深度研究表现。 使用便捷性:胜在全面和方便,各种功能还在不断新增中,包括api管理、多模型回答、联网搜索、知识库、MCP、导出到Obsidian等,直接给5星。 颜值:颜值尚可,4星。 多端体验:只有桌面端,不存在多端体验,2星。 综合评价:值得使用和关注,目前主要作为元宝的备选,最近使用频率随着元宝的增加而降低。
通义
使用便捷性:退出会弹出“再按一次退出应用”的提示,切换深度思考不方便,只能给2星★★。 颜值:不知道是更新了还是我之前没细心看,感觉颜值有4星★★★★。 日常问答表现:跟Kimi一样,先给3星★★★。 深度研究表现:未体验。 综合评价:也不知道阿里在干什么,想怎么干。
Others
大模型太多了,记录待评测。 ChatGPT:尝试过很多次,但还是用不了,只能干望。 Claude:用不出区别。 文小言:体验了一下深度搜索,效果稍微比国内几个好一些,可能跟搜索能力还是有一定关系。 智谱清言:待体验。 讯飞星火:待体验。 Monica:体验了一把,暂时没看到好用的地方。 Chatbox:用于通过OpenRouter的API体验GPT-4o。
笔记类大模型产品
Obsidian Copilot
AI能在笔记中到底应该怎么应用,目前还没有完全想清楚,还是觉得自己要能思考和输出才是最重要的,AI的助益实在是有限。这一个月主要还是用Obsidian Copilot用的多,直接说场景吧。 使用场景1:学习使用各种Obsidian插件,比如dataview插件的用法,我基本就是通过Copilot问出来的,目前用dataview这个插件解决了不少我的问题。 使用场景2:码字过程中碰到只了解大概或者不太确定的事情,可以随手查,非常快捷省事,比如在写《[[在雷军短暂登顶“中国首富”的这个当口,回首谈谈几件陈年旧事|在雷军短暂登顶“中国首富”的这个当口,回首谈谈几件陈年旧事]]》这篇文章,我对一些词汇和事件不太确定,就ai了一下,当然为了精准最终又用了元宝,因为Copilot还没解决联网的问题。 使用场景3:码字过程中碰到不太重要的说明性文字,直接ai生成内容并插入文档,比如《[[浅谈十二首最喜欢的诗词|浅谈十二首最喜欢的诗词]]》中,我就直接输入诗词名,然后导入ai的诗词原文和基础解释。 使用场景4:设置好prompt后,可以快捷调用ai总结提炼文献笔记,但是因为个人还是认为文献笔记要自己总结提炼,所以用得也不多,感觉意义不太大。 使用场景5:工作中记笔记,碰到不太懂的问题可以随手问ai,比较方便,虽然通过元宝也可以做到这一点。 综合评价:最近在完善自己的“卡片笔记”流程(具体见《[[基于Obsidian实践卢曼的卡片笔记法|基于Obsidian实践卢曼的卡片笔记法]]》),在之前的笔记分类基础上,进一步从“文献笔记”中分离出一个“备查笔记”的类别,因为发现并不是所有保存的资料都需要仔细研读和理解,有些内容和资料本来就只是供需要时查找的,这种内容只要能够在需要时被快速定位查找到就可以了,所以我命名为“备查笔记”。我在想,可能AI在笔记中能起的作用,也只能是帮我们快速定位这种“备查笔记”吧,而对于其他类型的笔记,其实还是要靠我们自己内化和吸收,才能有更好的效果。
腾讯ima.copilot
仍未发现流弊之处,还是之前的感受。
腾讯出品的云端知识库产品,确实也没有发现好用在哪里,可能也是因为我不想把知识库建在云端,没有上传文件,所以发现不了它的好处吧。
Get笔记
仍未发现流弊之处,还是之前的感受。
一个没有桌面端的笔记产品不能够叫做知识库,而真正的知识库还是要在电脑端做深度思考的,不能仅仅是移动端的灵感乍现,暂时未发现他的特别优秀之处。
Others
wolai AI:最新版暂未体验。 Notion AI:暂未体验。 Flomo:暂未体验。
大模型应用类产品
Github Copilot
感觉还行,既能辅助看代码,还能排查代码运行的问题,降低了使用编程能力解决问题的门槛。最近用它结合元宝给的Python代码解决了一个工作上的数据处理问题,省了不少时间,感觉还是有一点谱的。另外还用它来协助修改了公众号发文(包括本文)要用的css排版文件,虽然改不出来我想要的排版,但是能够改掉我不想要的排版,也是很不容易了,感觉还是不错的,但不是软件开发人员也无法深入评价。
即梦AI
感觉画图这块,有空可以深入研究下,用deepseek输出提示词,放到即梦中生成图片,感觉也不是不能用,就改也懒得改了,直接放到上一篇文章中了。
Trae
字节真是流弊,豆包桌面端套着chromi开发,Trae套着vs code开发,也是没谁了。和加持Github Copilot的vscode比起来,实在是没看出差别来。
Coze
主要是通过Coze给公众号接入了DeepSeek,其他的不知道还能怎么帮到我。
Others
WPS灵犀:感觉还是一般,只能说金山的产品经理总感觉差点意思。 WPS AI:本来还想用它写个公式,结果还是要额外收费的,放弃了。 纳米搜索:本来是放弃“百度一下,你就知道”之后,需要有个搜索引擎的平替,目前用下来感觉没有特别惊艳的地方,打开网页的速度没有百度快,可能会回到百度搜索也说不定。 汪仔:没用,暂不评价。
用了元宝后基本只是在Obsidian Copilot中用云服务厂商的api,而优化最好的就是硅基流动,结论和以前一样,所以以下内容没有更新。
大模型云服务产品
请注意:以下产品均为收费服务。
硅基流动
国内大模型API聚合平台,对个人用户友好,对Obsidian Copilot有优化,有嵌入模型,价格同等水平下可以优先考虑。
DeepSeek开放平台
DeepSeek官方的API服务,因为不稳定暂未使用。
OpenRouter
国外大模型API聚合平台,可以使用包括GPT、Claude、Gemini等模型的API服务,可以作为官方ChatGPT的平替,但是价格不便宜。
火山方舟
感觉是目前云厂商中大模型服务做的最好的,可使用DeepSeek、Kimi、豆包等模型API,还有模型微调、AI应用开发等功能,长期来看要在大模型方面深入实践的话,可以考虑使用。
Others
华为云Modelarts:已注册,没充钱,体验赠送token中。 阿里百炼:已注册,没充钱,体验赠送token中,还没找到哪里看用量和费用。 腾讯云:作为最早注册并充钱的云服务,我已经不知道腾讯云大模型云服务的产品名称应该是叫“知识引擎原子能力”还是叫“大模型知识引擎”,反正挺混乱的,DeepSeek限期免费体验已结束,但是也不知道在哪里看大模型的使用量和费用,同等价位下会果断转移到其他厂商,但会持续观望,毕竟用了腾讯云的对象存储。
结语
这段时间爆火的manus和mcp,应该是ai真正有潜力帮我们干活的方向,但是既没有码,也没有时间体验,而且好饭不怕晚,过段时间再专门体验一下吧
兴之所志
2025年3月27日